1. Projektziel
Dieses Projekt besteht darin, eine vollständige, realistische Cloud-Infrastruktur auf AWS zu entwerfen, zu automatisieren und mit Terraform zu deployen.
- Automatisierung der AWS-Infrastruktur mit Infrastructure as Code
- Anwendung von Netzwerk- und Security-Best-Practices
- Deployment einer funktionsfähigen Anwendung, die verbunden ist mit:
- einer Datenbank
- einem Cache
- einem Messaging-Service
- Sichere und kollaborative Verwaltung des Terraform-States
- Verstehen, wie AWS-Services in einem Gesamtsystem zusammenarbeiten
2. Architektur
Die Architektur bildet eine typische Multi-Tier-Struktur ab (Public/Private Netzwerkzonen, Bastion-Zugriff, Managed Backend-Services) und wird vollständig über Terraform reproduzierbar bereitgestellt.
- VPC (Custom Network)
- Public & Private Subnets
- Internet Gateway
- NAT Gateway
- Bastion Host
- Security Groups
- Elastic Beanstalk (Apache Tomcat)
- EC2 Backend
- RDS MySQL
- ElastiCache
- Amazon MQ
- Remote Backend in S3 für den Terraform-State
- Variables, Providers, (optional) Modules
- Saubere Trennung: Code (Git) vs. State (S3)
2-1 Flow einer Internet-Request – Schritt für Schritt (mit VPC/IGW/NAT/Bastion)
Wie eine Internet-Anfrage durch die AWS-Architektur fließt (End-to-End)
Der folgende Ablauf beschreibt Schritt für Schritt, wie eine Anfrage eines Benutzers aus dem Internet durch die AWS-Infrastruktur bis zur Datenbank verarbeitet wird und anschließend als Antwort wieder an den Benutzer zurückkehrt. Zusätzlich wird erklärt, wo zentrale AWS-Komponenten wie VPC, Internet Gateway, NAT Gateway und Bastion Host in diesem Prozess eingesetzt werden.
1) Benutzeranfrage aus dem Internet
Der Benutzer ruft die Webanwendung „Profile“ über seinen Browser auf
(z. B. https://profile.example.com).
Diese HTTP/HTTPS-Anfrage befindet sich zunächst vollständig im öffentlichen Internet.
2) Eintritt in AWS über das Internet Gateway (IGW)
Die Anfrage erreicht AWS über das Internet Gateway, das an die VPC angebunden ist. Das IGW stellt die Verbindung zwischen dem öffentlichen Internet und den öffentlichen Subnets innerhalb der VPC her. Ohne ein IGW wäre kein externer Zugriff auf die Anwendung möglich.
3) Weiterleitung in das Public Subnet (Load Balancer)
Im Public Subnet befindet sich der Application Load Balancer.
Dieses Subnet besitzt eine Route 0.0.0.0/0 → IGW und ist damit aus dem Internet erreichbar.
Der Load Balancer akzeptiert ausschließlich HTTP/HTTPS-Traffic und prüft diesen zusätzlich
über seine Security Group.
4) Übergabe der Anfrage an das Application Tier (Private Subnet)
Der Load Balancer leitet die Anfrage an die Applikationsserver weiter, auf denen die Java-Webanwendung „Profile“ läuft. Diese EC2-Instanzen befinden sich bewusst in einem Private Subnet und besitzen keine öffentliche IP-Adresse. Der Zugriff ist ausschließlich aus dem Load Balancer erlaubt.
5) Verarbeitung der Business-Logik
Die Anwendung verarbeitet die Anfrage und führt ihre Business-Logik aus. Je nach Anwendungsfall greift sie dabei auf interne Dienste wie Datenbank, Cache oder Message-Broker zu.
6) Zugriff auf das Data Tier (RDS)
Für persistente Daten verbindet sich die Anwendung mit der RDS MySQL-Datenbank,
die ebenfalls in einem Private Subnet liegt.
Die zugehörige Security Group erlaubt ausschließlich Verbindungen vom Application Tier
(z. B. Port 3306), wodurch ein direkter Internetzugriff auf die Datenbank ausgeschlossen ist.
7) Rückgabe der Antwort innerhalb der VPC
Die Datenbank sendet die angeforderten Daten zurück an die Anwendung. Die Anwendung erzeugt daraus die HTTP-Antwort (HTML oder JSON) und gibt sie an den Load Balancer zurück.
8) Antwort an den Benutzer über das Internet
Der Load Balancer sendet die Antwort über das Public Subnet und das Internet Gateway zurück an den Benutzer. Für den Benutzer wirkt dieser gesamte Prozess wie eine direkte Antwort der Webseite, obwohl im Hintergrund mehrere isolierte Sicherheits- und Netzwerkschichten beteiligt sind.
9) Rolle des NAT Gateways (Outbound-Traffic)
Das NAT Gateway wird nicht für Benutzeranfragen verwendet. Es ermöglicht Instanzen in Private Subnets, ausgehende Internetverbindungen aufzubauen, z. B. für System-Updates, Paketinstallationen oder externe API-Aufrufe, ohne selbst aus dem Internet erreichbar zu sein.
10) Rolle des Bastion Hosts (Administration)
Der Bastion Host dient ausschließlich administrativen Zwecken. Administratoren verbinden sich per SSH zunächst mit dem Bastion Host im Public Subnet und springen von dort gezielt auf EC2-Instanzen in den Private Subnets. Dadurch wird ein direkter SSH-Zugriff aus dem Internet auf interne Systeme vermieden.
Dieses Schema zeigt den kompletten Weg: User Request → Load Balancer → App (Private Subnet) → RDS → Response zurück. Zusätzlich: NAT Outbound (Updates) und Bastion Admin Path (SSH).
NAT ist nur für Outbound aus privaten Subnets (Updates, externe APIs).
Bastion ist nur für Admin/SSH – nicht für normalen User Traffic.
2.2 Architekturüberblick mit terraform integration
Infrastruktur
Anwendung & Services
2.2 Terraform – State & Struktur
Infrastruktur
Anwendung & Services
3. Funktionsweise des Gesamtsystems mit Terraform
- Terraform liest den Code und den in S3 gespeicherten State.
- Terraform erstellt die Netzwerk-Basis (VPC, Subnets, Routes).
- Öffentliche Ressourcen stellen den Application-Zugriff bereit.
- Private Ressourcen hosten Backend-Logik und Daten.
- Zugriffe werden strikt über Security Groups kontrolliert.
- Der Bastion Host ermöglicht sicheren administrativen Zugriff (SSH Jump).
- Die Anwendung kommuniziert mit DB, Cache und MQ.
terraform plan und terraform apply umgesetzt.
4. Praktischer Teil – Implementierungsschritte
4.1) Terraform Setup
- Ziel:
In diesem Abschnitt werden Projekt-Branch, Terraform-Installation und die AWS-Authentifizierung vorbereitet, damit Terraform die Infrastruktur über die AWS API automatisiert provisionieren kann.
- Vorgehen:
1) Projekt klonen & Branch erstellen
- Repository klonen und ins Projekt wechseln:
git clone https://github.com/<username>/profile.git
cd profile- Neuen Branch für Terraform anlegen:
git checkout -b terraform-project2) Terraform installieren (Windows)
- Chocolatey installieren (falls nicht vorhanden):
Set-ExecutionPolicy Bypass -Scope Process -Force
iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))- Terraform via Chocolatey installieren und Version prüfen:
choco install terraform
terraform -version3) AWS Zugriff einrichten (IAM User + Access Keys)
- AWS Console → IAM → Users → Create user
- User:
terraform-admin - Policy: AdministratorAccess
- Access Key über Security credentials von IAMUser erstellen (Use case: CLI) und sicher speichern
4) AWS CLI konfigurieren (lokale Credentials)
Terraform nutzt die lokal gespeicherten AWS Credentials (z.B. unter ~/.aws/credentials), um sich gegenüber AWS zu authentifizieren.
aws configure- AWS Access Key ID und Secret Access Key vom IAM User eingeben
- Output Format:
json
5) Ergebnis
- Terraform ist installiert
- AWS CLI ist konfiguriert
- Terraform kann nun über AWS API Ressourcen erstellen
4.2) S3 Remote Backend (Terraform State)
- Ziel:
Wenn Terraform-Code ausgeführt wird, speichert Terraform alle Informationen über die Infrastruktur im tfstate-File. Standardmäßig wird diese Datei im aktuellen Arbeitsverzeichnis abgelegt. Ziel dieses Schrittes ist es, den Terraform State (terraform.tfstate) zentral und sicher in einem AWS S3 Bucket zu speichern, um Teamarbeit, Reproduzierbarkeit und State-Locking zu ermöglichen.
- Vorgehen:
1) S3 Bucket für den Terraform State erstellen
- AWS Console → S3 → Create bucket
- Bucket Name:
terraformstate### - Region: z. B.
us-### - Ein Ordner
terraformin Bucket erstellen
3) Terraform Backend konfigurieren
Die Backend-Konfiguration wird im Terraform Code definiert,
z. B. in der Datei backend.tf.
- Das Projekt im VSCode öffnen und im Projektverzeichnis die Datei
backend.tferstellen.
terraform {
backend "s3" {
bucket = "terraformstate###"
key = "terraform/backend"
region = "us-###"
dynamodb_table = "terraform-lock"
encrypt = true
}
}- terraform definiert einen globalen Terraform-Konfigurationsblock, der grundlegende Einstellungen wie Backend oder Provider enthält.
- backend "s3" legt fest, dass der Terraform State nicht lokal, sondern zentral in einem Amazon S3 Bucket gespeichert wird.
-
bucket & key bestimmen den Speicherort des States:
bucketist der Name des S3 Buckets undkeyder Pfad, unter dem dieterraform.tfstate-Datei im Bucket abgelegt wird.
4) Terraform Backend initialisieren
Nach dem Hinzufügen oder Ändern der Backend-Konfiguration muss Terraform neu initialisiert werden. Git Bash und im Projektverzeichnis wechseln dann:
terraform init- Terraform verbindet sich mit S3
- Der State wird im Remote Backend angelegt oder gelesen
- Lokaler State wird nicht mehr verwendet
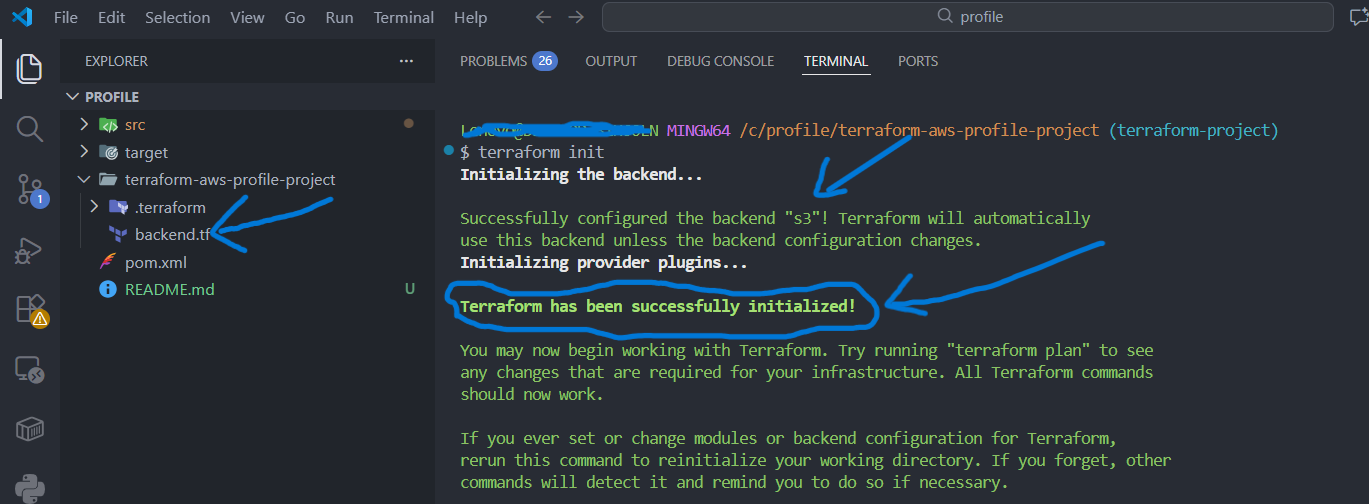
5) Ergebnis
- Terraform State liegt zentral in S3
- Mehrere Entwickler können sicher zusammenarbeiten
- State-Konflikte werden durch Locking vermieden
4.3) Variables & Provider (Terraform Grundlagen)
- Ziel:
Ziel dieses Schrittes ist es, die Terraform-Konfiguration flexibel, wiederverwendbar und umgebungsunabhängig zu gestalten, indem Variablen definiert und der AWS Provider korrekt konfiguriert werden.
- Vorgehen:
1) AWS Provider konfigurieren
Der Provider definiert, mit welchem Cloud-Anbieter Terraform kommuniziert.
In diesem Projekt wird der AWS Provider verwendet, um Ressourcen über die AWS API zu erstellen.
Im Projektverzeichnis providers.tf File erstellen:
provider "aws" {
region = var.AWS_REGION
}- Der AWS Provider stellt die Verbindung zwischen Terraform und AWS her
- Die Region wird über eine Variable gesteuert
2) Variablen definieren
Variablen ermöglichen es, Werte wie Region, Instanztyp oder Umgebungsnamen zentral zu definieren und mehrfach zu verwenden. Im weiteren Verlauf des Projekts werden zusätzliche Variablen ergänzt. In diesem Schritt wird zunächst die AWS-Region als Variable definiert.
variable "AWS_REGION" {
default = "us-###"
}- Variablen werden in der Regel in der Datei
vars.tfdefiniert - Sie erhöhen die Lesbarkeit, Wartbarkeit und Wiederverwendbarkeit des Codes
var.<name>greift auf den Variablenwert zu- Gleiche Konfiguration kann für mehrere Umgebungen genutzt werden
5) Ergebnis
- Terraform-Konfiguration ist flexibel und parametrisierbar
- Provider ist sauber von der Infrastrukturdefinition getrennt
- Code kann einfach für verschiedene Umgebungen wiederverwendet werden
4.4) Key Pairs (SSH-Zugriff auf EC2)
- Ziel:
Ziel dieses Schrittes ist es, einen sicheren SSH-Zugriff auf EC2-Instanzen zu ermöglichen, ohne Passwörter zu verwenden, indem ein SSH Key Pair für die Authentifizierung eingesetzt wird.
- Vorgehen:
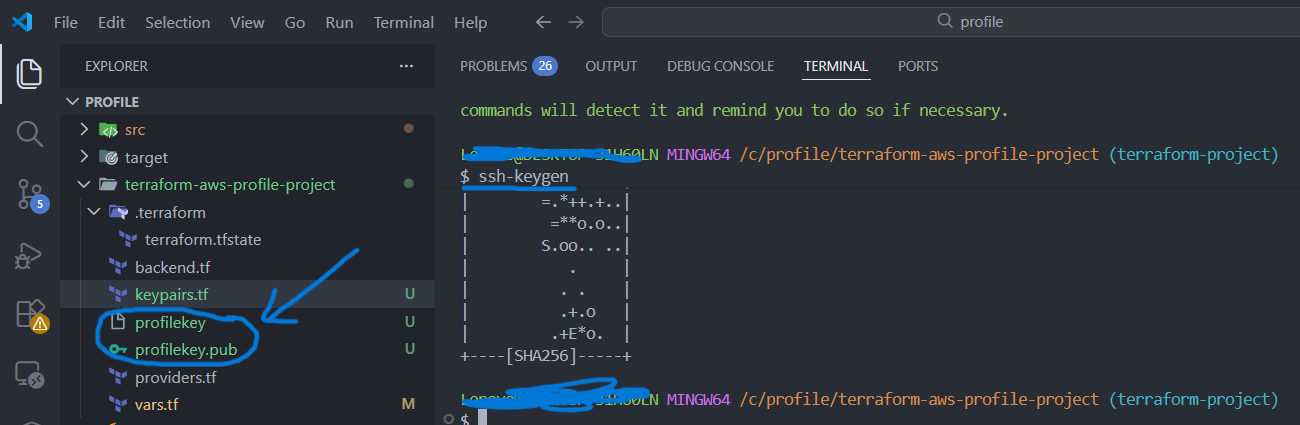
1) SSH Key Pair lokal erstellen
Ziel dieses Schrittes ist es, einen sicheren SSH-Zugriff auf EC2-Instanzen (Bastion Host, Elastic Beanstalk) zu ermöglichen, ohne Passwörter zu verwenden. Stattdessen wird eine SSH-Key-basierte Authentifizierung eingesetzt.
Das Key Pair wird lokal im Projektverzeichnis auf dem Entwicklerrechner erzeugt. Der private Schlüssel verbleibt ausschließlich lokal, während der öffentliche Schlüssel später in AWS hinterlegt wird. In Git Bash:
ssh-keygen
profilekeyprofilekey→ privater Schlüssel (bleibt lokal gespeichert)profilekey.pub→ öffentlicher Schlüssel (wird in AWS verwendet)
Git Bash im Projektverzeichnis öffnen und den obigen
ssh-keygen-Befehl ausführen.
Dadurch werden der private Schlüssel profilekey und der öffentliche Schlüssel
profilekey.pub automatisch im Projektverzeichnis erstellt.
Der öffentliche Schlüssel wird anschließend kopiert und für die Registrierung in AWS verwendet.
2) Public Key in AWS registrieren
Der öffentliche Schlüssel wird als Key Pair in AWS hinterlegt,
sodass EC2-Instanzen diesen für den SSH-Zugriff akzeptieren. Im Projektverzeichnis keypairs.tf File erstellen:
resource "aws_key_pair" "profilekey" {
key_name = "profilekey"
public_key = "Inhalt von profilekey.pub"
}Jetzt werden die folgenden Terraform-Befehle im Projektverzeichnis über Git Bash ausgeführt, um die Konfiguration zu prüfen und keypair(profilekey.pub) zu legen.
-
terraform init
Initialisiert das Terraform-Projekt, lädt den AWS Provider, konfiguriert das Remote Backend und bereitet das Arbeitsverzeichnis vor. -
terraform fmt
Formatiert den Terraform-Code automatisch nach Best Practices, um eine einheitliche und gut lesbare Struktur sicherzustellen. -
terraform validate
Überprüft die Terraform-Konfiguration auf syntaktische und logische Fehler, ohne Ressourcen zu erstellen oder zu verändern. -
terraform plan
Erstellt einen Ausführungsplan und zeigt an, welche Ressourcen erstellt, geändert oder gelöscht werden, bevor Änderungen in AWS durchgeführt werden. -
terraform apply
Führt den zuvor berechneten Plan aus und erstellt das definierte SSH Key Pair in AWS über die AWS API.
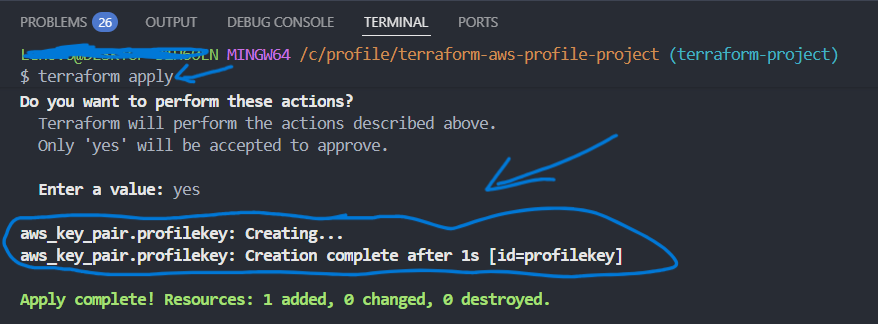

- Der Public Key wird automatisch in AWS importiert
- Kein manueller Upload über die AWS Console erforderlich
-
Terraform-Befehle folgen dem Prinzip:
init → fmt → validate → plan → apply,
um Infrastruktur sicher und kontrolliert bereitzustellen.
4.5) VPC Module & Setup
- Ziel:
Ziel dieses Schrittes ist es, eine isolierte und sichere Netzwerkbasis in AWS zu schaffen. Dazu wird eine eigene Virtual Private Cloud (VPC) mit Public- und Private-Subnets über ein Terraform-Modul bereitgestellt.
- Vorgehen:
1) Einsatz eines Terraform VPC Moduls
Um Best Practices einzuhalten und den Code übersichtlich zu halten,
wird die VPC nicht manuell definiert, sondern über ein wiederverwendbares
Terraform-Modul erstellt (Terraform Registry Doc). Im Projektverzeichnis vpc.tf File erstellen:
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
name = var.VPC_NAME
Name der VPC
cidr = var.VpcCIDR
IP-Adressbereich der VPC
azs = [var.Zone1, var.Zone2, var.Zone3]
Availability Zones
public_subnets = [var.PubSub1CIDR, var.PubSub2CIDR, var.PubSub3CIDR]
private_subnets = [var.PrivSub1CIDR, var.PrivSub2CIDR, var.PrivSub3CIDR]
enable_nat_gateway = true
single_nat_gateway = true
enable_dns_support = true
enable_dns_hostnames = true
map_public_ip_on_launch = true
Öffentliche IPs für Ressourcen in Public Subnets
tags = {
Name = var.VPC_NAME
Project = var.PROJECT
}
}
- Die VPC bildet das private Netzwerk für alle Ressourcen
- Für jede Availability Zone wird ein eigenes Public- und Private-Subnet erstellt
- NAT Gateways ermöglichen Internetzugriff aus Private Subnets
- DNS aktiviert Interne Namensauflösung
In Git Bash werden anschließend die Standard-Terraform-Kommandos ausgeführt:
terraform init, terraform fmt, terraform validate,
terraform plan und terraform apply.:
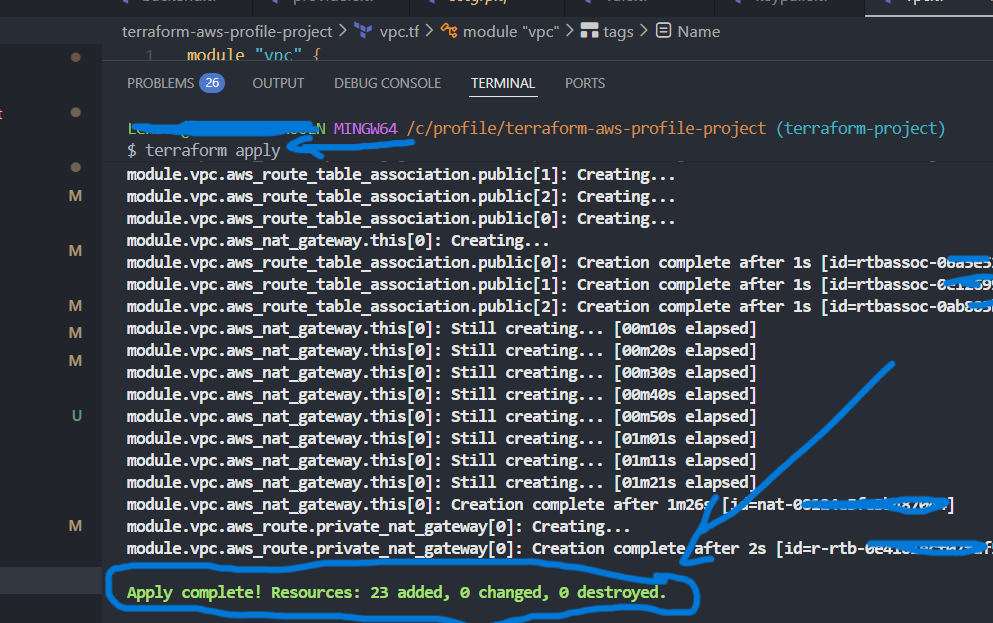

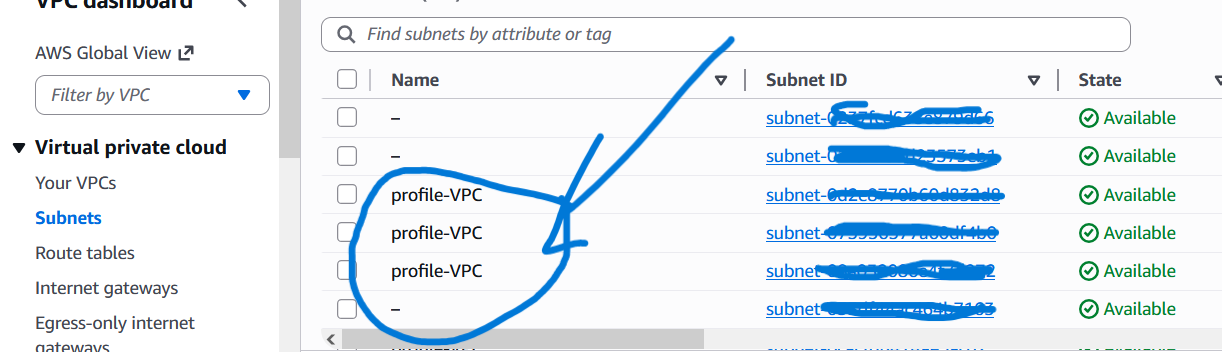
2) Ergebnis
- Isolierte AWS VPC mit klarer Netzwerksegmentierung
- Hohe Verfügbarkeit durch Nutzung mehrerer Availability Zones
- Sichere Trennung von öffentlichen und internen Ressourcen
4.6) Security Group Setup
- Ziel:
Ziel dieses Schrittes ist es, den Netzwerkzugriff innerhalb der AWS-Infrastruktur präzise zu steuern. Security Groups fungieren als virtuelle Firewalls und stellen sicher, dass nur explizit erlaubter Traffic zwischen Internet, Load Balancer, Bastion Host, Applikation und Datenbank fließen darf. Dadurch wird das Least-Privilege-Prinzip umgesetzt: Jede Komponente darf nur genau das, was sie wirklich benötigt.
- Vorgehen:
1) Grundprinzip von Security Groups
- Security Groups sind stateful (Antwort-Traffic ist automatisch erlaubt).
- Standardmäßig ist Inbound blockiert, bis Regeln explizit definiert werden.
- Regeln werden direkt an Ressourcen (z. B. EC2, ALB, RDS) gebunden.
- Best Practice: Zugriff intern über SG-zu-SG-Regeln statt offene IP-Ranges.
Das Diagramm zeigt, welche Security Group mit welcher anderen Komponente kommunizieren darf (Ports/Flow). Fokus: Least-Privilege (nur notwendige Ports, SG→SG statt offene IP-Ranges im internen Netz).
2) Security Group – Bastion Host
Der Bastion Host ist der einzige Einstiegspunkt für administrativen SSH-Zugriff aus dem Internet.
- Zweck: Sicherer SSH-Zugang zu privaten Ressourcen
- Inbound: SSH (22) → nur eigene IP
- Outbound: Standard (z. B. alles erlaubt)
3) Security Group – Load Balancer (ALB)
Der Load Balancer ist öffentlich erreichbar und nimmt Benutzeranfragen entgegen.
- Zweck: HTTP/HTTPS Ingress aus dem Internet
- Inbound: HTTP (80) & HTTPS (443) → 0.0.0.0/0
- Outbound: Weiterleitung an das Application Tier (nur App-SG)
4) Security Group – Application Tier (EC2 / Elastic Beanstalk)
Die Java-Webanwendung „Profile“ läuft in privaten Subnets und besitzt keine öffentliche IP. Zugriff erfolgt ausschließlich über den ALB bzw. über den Bastion Host für Admin-Zwecke.
- Zweck: Ausführung der Business-Logik
- Inbound: App-Port (HTTP/HTTPS) → nur vom ALB
- Inbound (Admin): SSH (22) → nur vom Bastion Host
- Outbound: All ipv4 and ipv6
5) Security Group – Backend (RDS, cache, amazon mq )
Die Datenbank ist das sensibelste Element der Architektur und wird vollständig abgeschottet betrieben.
- Zweck: Persistente Datenspeicherung
- Inbound:from 0 bis 65535→ von der App-SG
- Inbound: MySQL (3306) → vom Bastion Host
- Outbound: All ipv4 and ipv6
- Inbound:from 0 bis 65535→ von der Backend-SG, (der internen Backend-Kommunikation)
6) Umsetzung mit Terraform
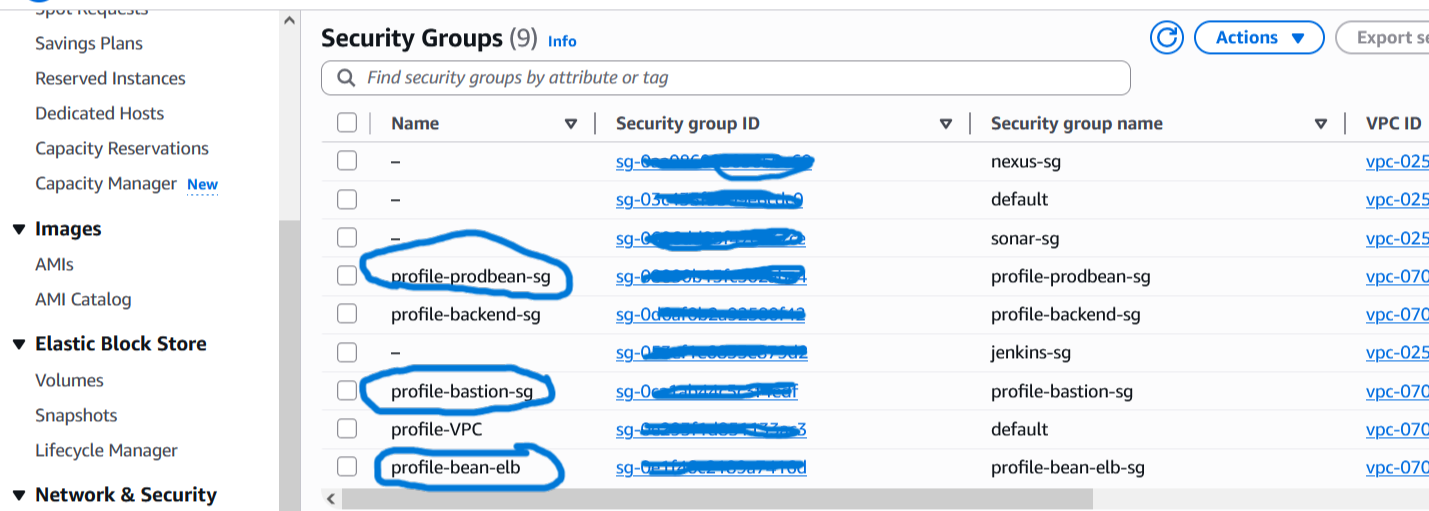
Alle Security Groups werden als Code in der Datei secgrp.tf definiert.
Dadurch ist die gesamte Netzwerk-Sicherheitslogik reproduzierbar, versionierbar
und vollständig über Terraform steuerbar.
Das folgende Beispiel zeigt einen Ausschnitt aus der Datei secgrp.tf.
Die vollständige Datei enthält zusätzlich weitere Security Groups und Regeln
(z. B. für Bastion Host, Application Tier und Datenbank).
resource "aws_security_group" "profile-bean-elb-sg" {
name = "profile-bean-elb-sg"
description = "Security group for bean-elb"
vpc_id = module.vpc.vpc_id
tags = {
Name = "profile-bean-elb"
ManagedBy = "Terraform"
Project = "profile"
}
}
resource "aws_vpc_security_group_ingress_rule" "allow_http_forELB" {
security_group_id = aws_security_group.profile-bean-elb-sg.id
cidr_ipv4 = "0.0.0.0/0"
ip_protocol = "tcp"
from_port = 80
to_port = 80
}Kurze Erklärung (einfach & praxisnah)
-
aws_security_grouperstellt eine Security Group für den Elastic Load Balancer der Anwendung. -
vpc_id = module.vpc.vpc_idstellt sicher, dass die Security Group in der richtigen VPC erstellt wird. -
tagsdienen der Identifikation, Strukturierung und Governance (Projekt, Owner, Automation). -
aws_vpc_security_group_ingress_ruledefiniert eine einzelne Inbound-Regel. -
Der Port
80wird aus dem Internet (0.0.0.0/0) für HTTP-Traffic zum Load Balancer freigegeben.
Dieser Code stellt nur einen kleinen Teil der gesamten
secgrp.tf-Datei dar.
Alle weiteren Security Groups (Bastion, Application, RDS) sowie deren
Kommunikationsregeln sind vollständig in dieser Datei definiert.
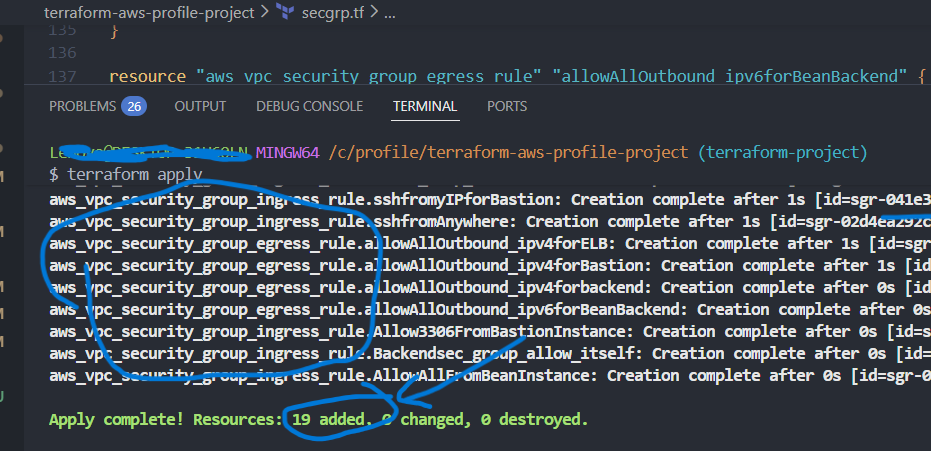
In Git Bash werden anschließend die Standard-Terraform-Kommandos ausgeführt:
terraform init, terraform fmt, terraform validate,
terraform plan und terraform apply.:
4.7) RDS, ElastiCache & Amazon MQ
- Ziel:
Ziel dieses Schrittes ist es, die Backend-Services der Java-Webanwendung „Profile“ bereitzustellen. Dazu gehören eine relationale Datenbank (RDS MySQL), ein In-Memory-Cache (ElastiCache) sowie ein Message-Broker (Amazon MQ).
Alle Services werden ausschließlich in Private Subnets betrieben und sind nur für das Application Tier erreichbar.
- Vorgehen:
1) Grundprinzip (Private Backend-Services)
- Backend-Services besitzen keine öffentliche IP
- Zugriff nur über definierte Security Groups
- Isolation durch Private Subnets
- Trennung von Application- und Data-Layer
Alle Ressourcen für diesen Abschnitt sind im Terraform-File
backend-services.tf definiert.
2) Subnet Groups erstellen
AWS Managed Services wie RDS, ElastiCache und Amazon MQ benötigen eigene Subnet Groups, um festzulegen, in welchen Subnets sie betrieben werden dürfen.
- Subnet Groups enthalten ausschließlich Private Subnets
- Ermöglichen Hochverfügbarkeit und Isolation
Subnet Groups in backend-services.tf
resource "aws_db_subnet_group" "profile-rds-subgrp" {
name = "profile-rds-subgrp"
subnet_ids = [module.vpc.private_subnets[0], module.vpc.private_subnets[1], module.vpc.private_subnets[2]]
tags = {
Name = "Subnet group for RDS"
}
}
resource "aws_elasticache_subnet_group" "profile-ecache-subgrp" {
name = "profile-ecache-subgrp"
subnet_ids = [module.vpc.private_subnets[0], module.vpc.private_subnets[1], module.vpc.private_subnets[2]]
tags = {
Name = "Subnet group for Elasticache"
}
}- Über
subnet_idswird erzwungen, dass RDS/Cache nur in Private Subnets laufen.
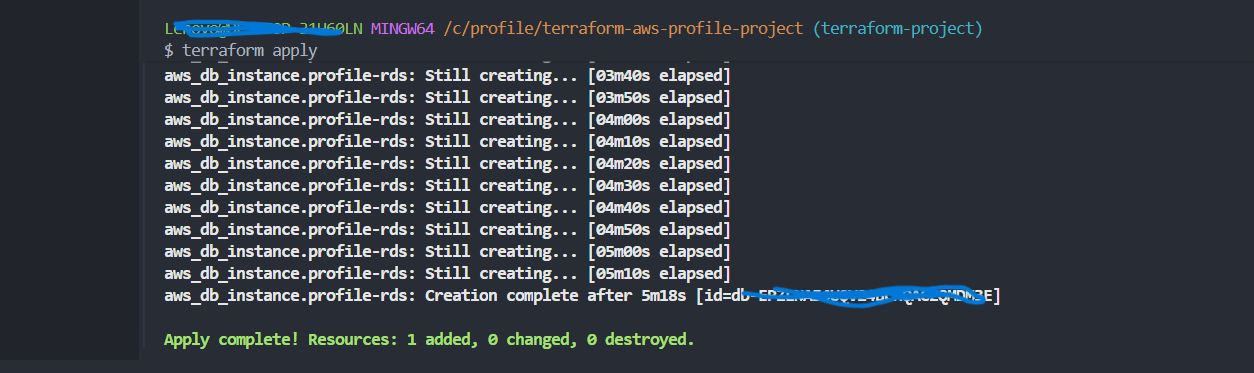
3) RDS MySQL
RDS stellt die relationale Datenbank für die Anwendung bereit und übernimmt Backups, Patching und optional Multi-AZ-Failover.
- Engine: MySQL
RDS Instance in backend-services.tf
resource "aws_db_instance" "profile-rds" {
allocated_storage = 20
storage_type = "gp3"
engine = "mysql"
engine_version = "8.0.39"
instance_class = "db.t4g.micro"
db_name = var.dbname
username = var.dbuser
password = var.dbpass
parameter_group_name = "default.mysql8.0"
multi_az = "false"
publicly_accessible = "false"
skip_final_snapshot = true
db_subnet_group_name = aws_db_subnet_group.profile-rds-subgrp.name
vpc_security_group_ids = [aws_security_group.profile-backend-sg.id]
}- Kein Public Access:
publicly_accessible = "false"verhindert Internetzugriff auf die Datenbank. - Netzwerkbindung:
db_subnet_group_nameplatziert RDS in den Private Subnets der VPC. - Zugriffskontrolle:
vpc_security_group_idsbegrenzt DB-Zugriff auf die definierte Backend-SG (Port 3306 kommt über SG-Regeln).
4) ElastiCache – In-Memory Cache
ElastiCache reduziert die Last auf der Datenbank und verbessert die Antwortzeiten der Anwendung.
- Engine: Memcached (im Projekt umgesetzt)
ElastiCache Cluster in backend-services.tf
resource "aws_elasticache_cluster" "profile-cache" {
cluster_id = "profile-cache"
engine = "memcached"
node_type = "cache.t3.micro"
engine_version = "1.6.22"
num_cache_nodes = 1
parameter_group_name = "default.memcached1.6"
port = 11211
security_group_ids = [aws_security_group.profile-backend-sg.id]
subnet_group_name = aws_elasticache_subnet_group.profile-ecache-subgrp.name
}- Privates Placement:
subnet_group_namebindet den Cache an Private Subnets (kein direkter Internetzugriff). - Port & Security:
port = 11211+security_group_idsstellt sicher, dass nur erlaubte interne Clients zugreifen können. - Ressourcengröße:
node_typeundnum_cache_nodesbestimmen Performance/Kosten
5) Amazon MQ – Message Broker
Amazon MQ ermöglicht asynchrone Verarbeitung und entkoppelt Anwendungskomponenten.
- Broker: RabbitMQ (im Projekt umgesetzt)
- Placement: Private Subnets
- Nutzen: Asynchrone Kommunikation
Amazon MQ Broker in backend-services.tf
resource "aws_mq_broker" "profile-rmq" {
broker_name = "profile-rmq"
engine_type = "RabbitMQ"
engine_version = "3.13"
host_instance_type = "mq.t3.micro"
auto_minor_version_upgrade = true
security_groups = [aws_security_group.profile-backend-sg.id]
subnet_ids = [module.vpc.private_subnets[0]]
user {
username = var.rmquser
password = var.rmqpass
}
}- Private Subnet:
subnet_idsplatziert den Broker im Private Subnet (keine öffentliche Erreichbarkeit). - Security Group:
security_groupsbegrenzt, wer die Broker-Ports erreichen darf (typisch: nur App-Tier). - Credentials als Variablen:
usernutztvar.rmquser/var.rmqpass, damit keine Zugangsdaten im Code hardcodiert sind.
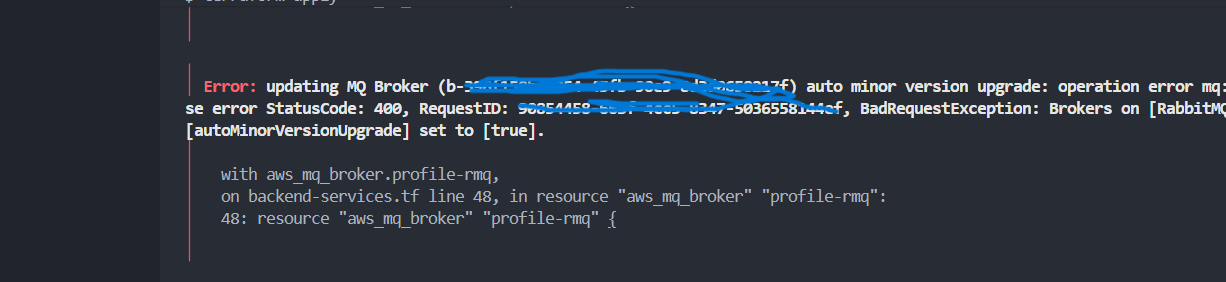
Problem: Die Erstellung des Amazon MQ Brokers (RabbitMQ 3.13) ist fehlgeschlagen, da die Option
auto minor version upgrade nicht aktiviert war, obwohl sie für diese Version erforderlich ist.
Lösung: Setzen von auto_minor_version_upgrade = true in der Ressource
aws_mq_broker und erneutes Ausführen von terraform apply.
4.8) Elastic Beanstalk Environment Setup
- Ziel:
Ziel dieses Schrittes ist es, ein Elastic Beanstalk Environment für die Java-Webanwendung „Profile“ bereitzustellen. Elastic Beanstalk übernimmt dabei das Application Deployment, das Lifecycle-Management sowie die Integration mit dem Application Load Balancer und den EC2-Instanzen.
Das Environment läuft vollständig innerhalb der bestehenden VPC und nutzt Private Subnets für die EC2-Instanzen.
- Vorgehen:
1) Architekturprinzip
- Elastic Beanstalk verwaltet EC2-Instanzen automatisch (autoscaling)
- Application Load Balancer im Public Subnet
- EC2 Application Server im Private Subnet
- Integration mit bestehenden Security Groups
- Kein direkter Internetzugriff auf EC2
In diesem Projekt gibt es zwei Terraform-Ressourcen: Beanstalk Application (logischer Container) und Beanstalk Environment (reale Laufzeitumgebung). Das Environment erzeugt und verwaltet die eigentlichen AWS-Komponenten wie Load Balancer, Auto Scaling und EC2-Instanzen.
bean-env.tf erstellt das Environment (ALB + ASG + EC2) und verbindet es mit VPC/Subnets/SG.
Deployments passieren über Application Versions (z. B. WAR), die im Environment ausgerollt werden.
2) Elastic Beanstalk Application (bean-app.tf)
Die Beanstalk Application ist ein logischer Container für ein oder mehrere Environments (z. B. Dev, Test, Prod).
resource "aws_elastic_beanstalk_application" "profile-app" {
name = "profile-app"
description = "Elastic Beanstalk Application for Profile Java WebApp"
}- Wiederverwendbar: Mehrere Environments (Dev/Prod) möglich.
- Vollständig versionierbar und reproduzierbar.
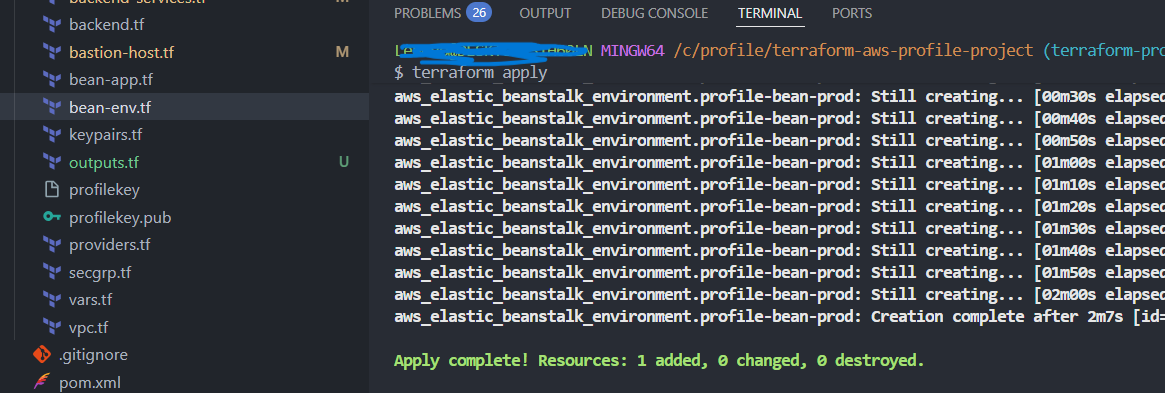
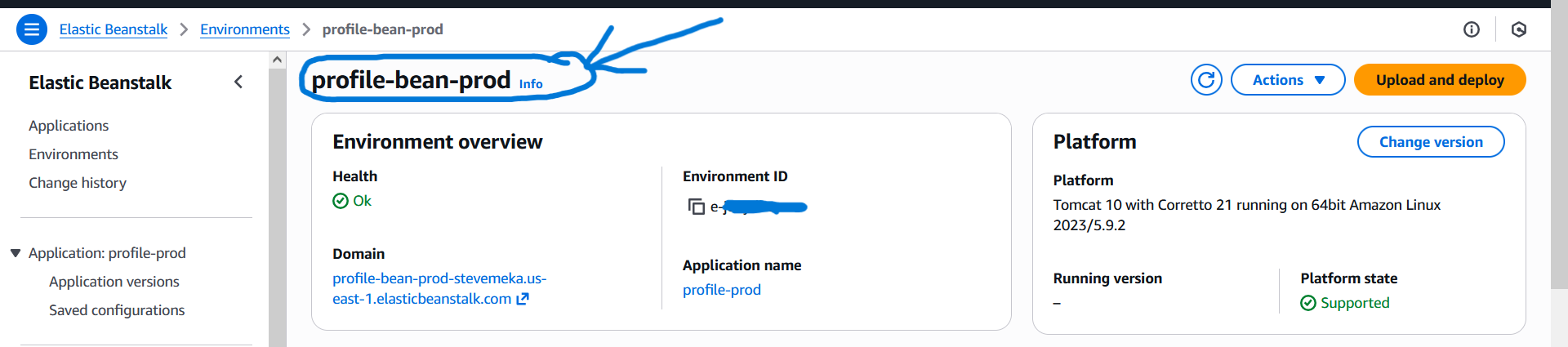
3) Elastic Beanstalk Environment (bean-env.tf)
Das Environment beschreibt die tatsächliche Laufzeitumgebung: EC2-Instanzen, Load Balancer, Netzwerkeinstellungen und Plattform.
resource "aws_elastic_beanstalk_environment" "profile-env" {
name = "profile-prod-env"
application = aws_elastic_beanstalk_application.profile-app.name
solution_stack_name = "64bit Amazon Linux 2 v5.8.4 running Tomcat 9 Corretto 17"
setting {
namespace = "aws:ec2:vpc"
name = "VPCId"
value = module.vpc.vpc_id
}
setting {
namespace = "aws:ec2:vpc"
name = "Subnets"
value = join(",", module.vpc.private_subnets)
}
setting {
namespace = "aws:ec2:vpc"
name = "ELBSubnets"
value = join(",", module.vpc.public_subnets)
}
...
}-
VPC-Anbindung:
Das Setting
VPCIdbindet das Elastic-Beanstalk-Environment an die bestehende VPC, die zuvor mit Terraform erstellt wurde. -
Private EC2-Instanzen:
Über
Subnetswerden die Application-Server (EC2) ausschließlich in Private Subnets platziert. Dadurch sind sie nicht direkt aus dem Internet erreichbar. -
Öffentlicher Load Balancer:
Das Setting
ELBSubnetssorgt dafür, dass der Application Load Balancer in den Public Subnets erstellt wird und als einziger Einstiegspunkt für Benutzeranfragen dient.
In der Datei bean-env.tf sind zusätzlich weitere Settings definiert,
unter anderem für Auto Scaling, Security, Deployment-Strategien und Health Checks.
Am Ende der Resource wird ein depends_on-Block verwendet,
um sicherzustellen, dass die benötigten Security Groups
(Load Balancer SG und Backend/ProdBean SG)
bereits existieren, bevor das Elastic-Beanstalk-Environment erstellt wird.
4.9) Bastion Host & DB Initialization
- Ziel:
Ziel dieses Schrittes ist es, einen Bastion Host für den sicheren administrativen Zugriff auf Ressourcen in den Private Subnets bereitzustellen und anschließend die Initialisierung der RDS-Datenbank durchzuführen.
Der Bastion Host fungiert als kontrollierter Einstiegspunkt (SSH Jump Host), über den Administratoren auf interne Systeme zugreifen können, ohne diese direkt aus dem Internet erreichbar zu machen.
- Vorgehen:
1) Architekturprinzip
- Bastion Host befindet sich im Public Subnet
- Private EC2 und RDS bleiben vollständig isoliert
- SSH-Zugriff erfolgt ausschließlich über den Bastion Host
- Datenbank wird einmalig initialisiert (Schema & Basisdaten)
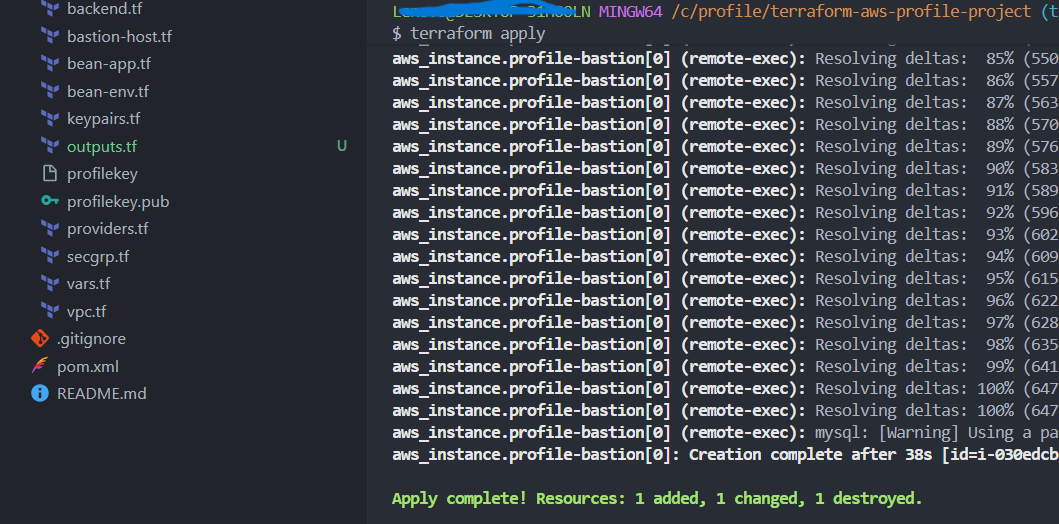
Dieses Schema zeigt den Admin-Zugriff über den Bastion Host (Public Subnet) in das Private Subnet sowie die DB-Initialisierung auf RDS MySQL. Die Datenbank bleibt dabei vollständig privat (kein Internet-Inbound).
2) Bastion Host bereitstellen (bastion-host.tf)
Der Bastion Host ist eine schlanke EC2-Instanz im Public Subnet, die als einziger SSH-Einstiegspunkt dient. In diesem Projekt wird sie zusätzlich genutzt, um die RDS-Datenbank initial zu konfigurieren (DB-Init Script).
-
AMI automatisch aktuell:
Über
data "aws_ami"wird immer die neueste Ubuntu 22.04 AMI von Canonical gewählt (most_recent = true+ Owner Canonical). -
Public Subnet + SSH:
Die Bastion liegt im
public_subnetsund ist über SSH erreichbar, damit Terraform perfileundremote-execProvisioner das DB-Init Script ausrollen kann. DB-Initialisierung automatisiert: Mit Hilfe von Terraform-Provisioners wird das Script aus einem Template generiert (
templatefile), auf die Bastion kopiert und ausgeführt, um die RDS-Datenbank automatisch zu initialisieren (Schema/Basisdaten).
Dafür wird im Projektverzeichnis ein Ordner templates/ angelegt,
der das Template db-deploy.tmpl enthält.
Dieses Template dient als Vorlage für das Datenbank-Initialisierungsskript.
provisioner "file" {
content = templatefile("templates/db-deploy.tmpl", {
rds-endpoint = aws_db_instance.profile-rds.address,
dbuser = var.dbuser,
dbpass = var.dbpass
})
destination = "/tmp/profile-dbdeploy.sh"
}
connection {
type = "ssh"
user = var.USERNAME
private_key = file(var.PRIV_KEY_PATH)
host = self.public_ip
}
provisioner "remote-exec" {
inline = [
"chmod +x /tmp/profile-dbdeploy.sh",
"sudo /tmp/profile-dbdeploy.sh"
]
}-
Template-Struktur:
Das Verzeichnis
templates/enthält die Dateidb-deploy.tmpl, welche als Vorlage für das Shell-Skript dient. -
Dynamische Generierung:
templatefile()ersetzt Platzhalter im Template durch echte Werte wie RDS-Endpunkt und Zugangsdaten. -
Übertragung & Verbindung:
Terraform baut per SSH eine Verbindung zur Bastion auf
und kopiert das generierte Skript nach
/tmp. - Automatische Initialisierung: Das Skript wird ausführbar gemacht und mit Root-Rechten ausgeführt, um die Datenbank initial zu konfigurieren.
4.9) Artifact Deployment
- Ziel:
Ziel dieses Schrittes ist es, das Build-Artefakt der Java-Webanwendung „Profile“ (WAR-Datei) kontrolliert und reproduzierbar in das Elastic Beanstalk Environment zu deployen.
Dabei wird bewusst zwischen Infrastruktur-Provisionierung (Terraform) und Applikations-Deployment (Artefakt-Rollout) getrennt.
- Vorgehen:
1) Git Bash öffnen & Branch prüfen
Zunächst wird sichergestellt, dass im richtigen Projektkontext und im korrekten Branch gearbeitet wird.
- Git Bash im Projektverzeichnis öffnen
- Sicherstellen, dass der Branch
terraform-projectaktiv ist
2) Terraform Outputs definieren (Endpoints sichtbar machen)
Um die Endpunkte der Backend-Services (RDS, ElastiCache, Amazon MQ)
einfach weiterverwenden zu können, wird eine Datei
outputs.tf im Projektverzeichnis angelegt.
output "rds_endpoint" {
value = aws_db_instance.profile-rds.address
}
output "cache_endpoint" {
value = aws_elasticache_cluster.profile-cache.cache_nodes[0].address
}
output "mq_endpoint" {
value = aws_mq_broker.profile-rmq.instances[0].endpoints[0]
}-
Warum?
- Terraform Outputs liefern die echten Service-Endpunkte
- Vermeidet Hardcoding von IPs oder DNS-Namen
- Erleichtert die Konfiguration der Anwendung
3) Application-Konfiguration anpassen
Die Anwendung benötigt die realen Endpunkte der Backend-Services.
Diese werden in der Datei application.properties hinterlegt.
vim src/main/resources/application.properties- Ersetzen aller Platzhalter durch die Terraform Outputs
- RDS Endpoint → Datenbank-Konfiguration
- Cache Endpoint → Memcache/Redis
- MQ Endpoint → RabbitMQ
-
Warum?
Die Anwendung muss wissen, wo sich ihre Backend-Services befinden, um korrekt starten zu können.
4) Build des Applikations-Artefakts
Nachdem die Konfiguration aktualisiert wurde, wird die Anwendung lokal gebaut.
mvn clean install- Erzeugt ein sauberes Build ohne alte Artefakte
- Validiert Abhängigkeiten und Code
- Erstellt das finale WAR-File
Das erzeugte Artefakt befindet sich anschließend im Verzeichnis
target/:
target/profile-v2.war-
Warum?
Elastic Beanstalk benötigt ein deploybares Artefakt (WAR-Datei für Tomcat).
5) Deployment in Elastic Beanstalk
Das erzeugte WAR-File wird nun in das Elastic Beanstalk Environment hochgeladen, das zuvor vollständig mit Terraform erstellt wurde.
- AWS Console → Elastic Beanstalk
- Environment auswählen (prod)
- Upload and Deploy wählen
profile-v2.warauswählen- Deployment starten
Ergebnis
- Applikation läuft im produktiven Beanstalk Environment
- Backend-Services sind korrekt angebunden
- Deployment ohne manuelle Server-Konfiguration
- Saubere Trennung von Infrastruktur, Konfiguration und Anwendung
5. Fazit
Dieses Projekt demonstriert eine vollständige Cloud-Architektur auf AWS, die mit Terraform automatisiert bereitgestellt wird. Dabei werden Security- und Netzwerk-Best-Practices umgesetzt, Managed Services integriert und eine funktionsfähige Anwendung deployed.